MiMo-VL – 小米开源的多模态大模型
芊芊下载2025-06-06 17:50:4175次浏览
MiMo-VL是什么
MiMo-VL 是小米开源的多模态大模型,由视觉编码器、跨模态投影层和语言模型构成,视觉编码器基于Qwen2.5-ViT,语言模型是小米自研的MiMo-7B。采用多阶段预训练策略,使用2.4T tokens的多模态数据,通过混合在线强化学习提升性能。在基础视觉理解、复杂推理、GUI交互等任务上表现出色,如在MMMU-val上达66.7%,超越Gemma 3 27B;在OlympiadBench上达59.4%,超越72B模型。
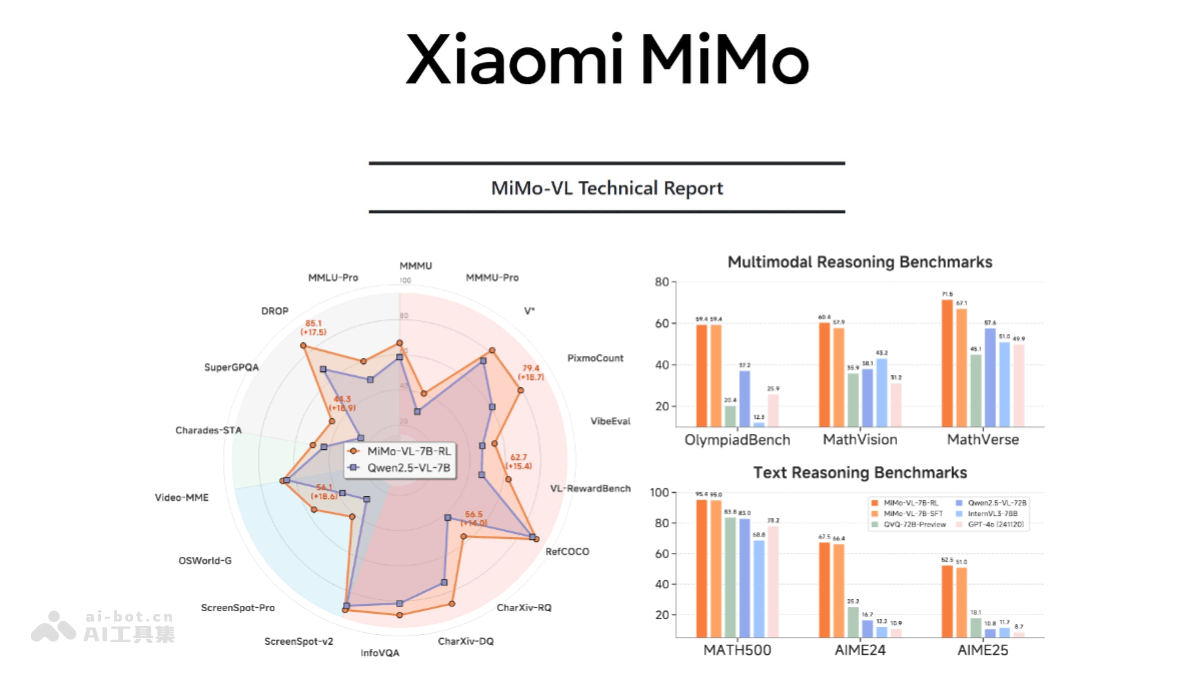
MiMo-VL的主要功能
- 复杂图片推理与问答:能对复杂图片进行推理和问答,准确理解图片内容并给出合理解释和答案。
- GUI 操作与交互:支持长达 10 多步的 GUI 操作,能理解和执行复杂的图形用户界面操作指令。
- 视频与语言理解:能理解视频内容,结合语言进行推理和问答。
- 长文档解析与推理:能处理长文档,进行复杂的推理和分析。
- 用户体验优化:通过混合在线强化学习算法(MORL),全方位提升模型的推理、感知性能和用户体验。
MiMo-VL的技术原理
- 视觉编码器:基于 Qwen2.5-ViT,支持原生分辨率输入,保留更多细节。
- 跨模态投影层:使用 MLP 结构实现视觉与语言特征的对齐。
- 语言模型:采用小米自研的 MiMo-7B 基础模型,专为复杂推理优化。
- 多阶段预训练:收集、清洗、合成了高质量的预训练多模态数据,涵盖图片-文本对、视频-文本对、GUI 操作序列等数据类型,总计 2.4T tokens。通过分阶段调整不同类型数据的比例,强化长程多模态推理的能力。
- 四阶段预训练:
- 投影层预热:使用图文对数据,序列长度为 8K。
- 视觉-语言对齐:使用图文交错数据,序列长度为 8K。
- 多模态预训练:使用 OCR/视频/GUI/推理数据,序列长度为 8K。
- 长上下文 SFT:使用高分辨率图像/长文档/长推理链,序列长度为 32K。
MiMo-VL的项目地址
- Github仓库:https://github.com/XiaomiMiMo/MiMo-VL
- HuggingFace模型库:https://huggingface.co/collections/XiaomiMiMo/mimo-vl
MiMo-VL的应用场景
- 智能客服:能完成复杂图片推理和问答等任务,为用户提供更加智能、便捷的服务。
- 智能家居:通过对家庭照片、视频等多媒体数据的理解,实现 GUI Grounding 任务,提高人机交互的效率和体验。
- 智能医疗:通过对医学图像和文本的理解,辅助医生进行诊断和治疗。
- 教育领域:辅助数学解题和编程学习,提供解题步骤和代码示例。
- 科研与学术:协助逻辑推理和算法开发,帮助研究人员验证假设和设计实验。
随机内容
↑