OmniAudio – 阿里通义推出的空间音频生成模型
芊芊下载2025-06-06 17:50:0877次浏览
OmniAudio是什么
OmniAudio 是阿里巴巴通义实验室语音团队推出的从360°视频生成空间音频(FOA)的技术。为虚拟现实和沉浸式娱乐提供更真实的音频体验。通过构建大规模数据集Sphere360,包含超过10.3万个视频片段,涵盖288种音频事件,总时长288小时,为模型训练提供了丰富资源。OmniAudio 的训练分为两个阶段:自监督的coarse-to-fine流匹配预训练,基于大规模非空间音频资源进行自监督学习;以及基于双分支视频表示的有监督微调,强化模型对声源方向的表征能力。
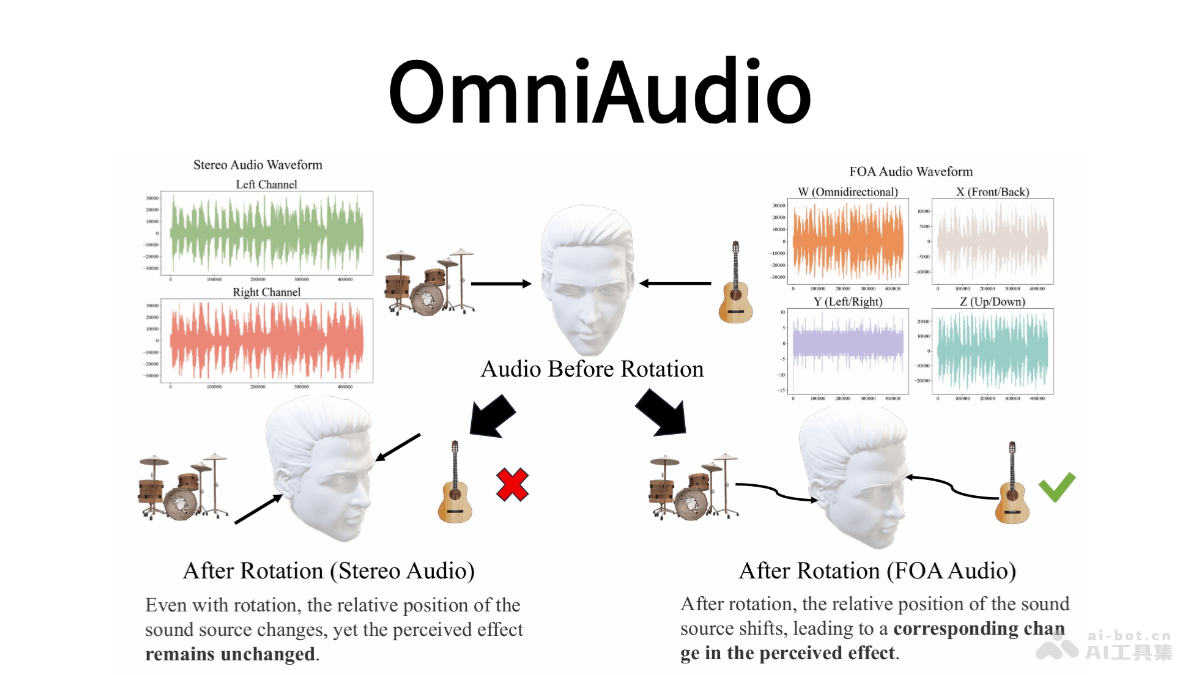
OmniAudio的主要功能
-
生成空间音频:能直接从360°视频生成FOA音频,这种音频是一种标准的3D空间音频格式,能捕捉声音的方向性,实现真实的3D音频再现。采用四个通道(W、X、Y、Z)来表示声音,其中W通道负责捕捉整体声压,X、Y、Z通道则分别捕捉前后、左右以及垂直方向的声音信息。在头部旋转时,可以确保声音定位的准确性得以保持。
-
提升沉浸式体验:为虚拟现实和沉浸式娱乐带来了全新的可能性。可以解决传统视频到音频生成技术主要生成非空间音频,无法满足沉浸式体验对3D声音定位需求的问题。
OmniAudio的技术原理
- 自监督的 coarse-to-fine 流匹配预训练
-
数据处理:由于真实FOA数据稀缺,研究团队利用大规模非空间音频资源(如 FreeSound、AudioSet、VGGSound 等),将立体声转换为“伪FOA”格式。具体来说,W通道为左右声道之和,X通道为左右声道之差,Y、Z通道置零。
-
模型训练:将转换后的“伪FOA”音频送入四通道VAE编码器获得潜在表示,然后以一定概率进行随机时间窗掩码,并将掩码后的潜在序列与完整序列一同作为条件输入至流匹配模型。模型通过最小化掩码前后潜在状态的速度场差异,实现对音频时序和结构的自监督学习。这一阶段使模型掌握了通用音频特征和宏观时域规律,为后续空间音频的精细化提供了基础。
- 基于双分支视频表示的有监督微调
-
数据利用:仅使用真实的FOA音频数据,继续沿用掩码流匹配的训练框架,但此时模型的全部注意力集中在四通道的空间特性上。
-
模型强化:通过对真实FOA潜在序列进行更高概率的掩码,强化了对声源方向(W/X/Y/Z四通道之间的互补关系)的表征能力,在解码端提升了对高保真空间音频细节的重建效果。
-
双分支结合:完成自监督预训练后,将模型与双分支视频编码器结合。针对输入的360°全景视频,使用冻结的MetaCLIP-Huge图像编码器提取全局特征;同时,从同一视频中裁取FOV局部视角,同样通过该编码器获取局部细节表征。全局特征经最大池化后作为Transformer的全局条件,局部特征经时间上采样后与音频潜在序列逐元素相加,作为逐步生成过程中的局部条件。
-
微调与输出:在保持预训练初始化参数大致走向的前提下,高效微调条件流场,从噪声中精准地“雕刻”出符合视觉指示的FOA潜在轨迹。微调完成后,在推理阶段只需采样学得的速度场,再经VAE解码器恢复波形,就能输出与360°视频高度对齐、具备精确方向感的四通道空间音频。
OmniAudio的项目地址
- 项目官网:https://omniaudio-360v2sa.github.io/
- Github仓库:https://github.com/liuhuadai/OmniAudio
- arXiv技术论文:https://arxiv.org/pdf/2504.14906
OmniAudio的应用场景
-
虚拟现实(VR)和沉浸式体验:OmniAudio 能为 VR 内容生成与视觉场景高度匹配的空间音频,增强用户的沉浸感。
-
360°视频配乐:为360°全景视频自动生成沉浸式音效,使观众在观看视频时能获得更真实的听觉体验。
-
智能语音助手:集成到智能家居设备中,如智能音箱、智能家电等,实现语音控制和交互。用户可以通过语音指令控制家电的开关、调节温度、查询信息等。
-
机器人和自动驾驶领域:OmniAudio 可以应用于机器人和自动驾驶领域,为这些系统提供更准确的声音定位和环境感知。
随机内容
↑