VikingDB – 火山引擎推出的大规模云原生向量数据库
芊芊下载2025-07-16 15:44:4964次浏览
VikingDB是什么
VikingDB 是火山引擎推出的高性能向量数据库,专为处理海量高维向量数据设计。VikingDB 支持实时同步、异步写入等多种数据写入方式,具备自研的 HNSW、IVF 等高效索引算法,可实现百亿级向量的毫秒级检索,兼容稠密与稀疏向量检索。VikingDB 提供 SaaS 控制台、API 和多种语言的 SDK,支持自动弹性扩容,广泛应用在多模态搜索、智能推荐、RAG 场景及记忆库构建等领域,助力企业实现高效数据管理和智能应用开发。
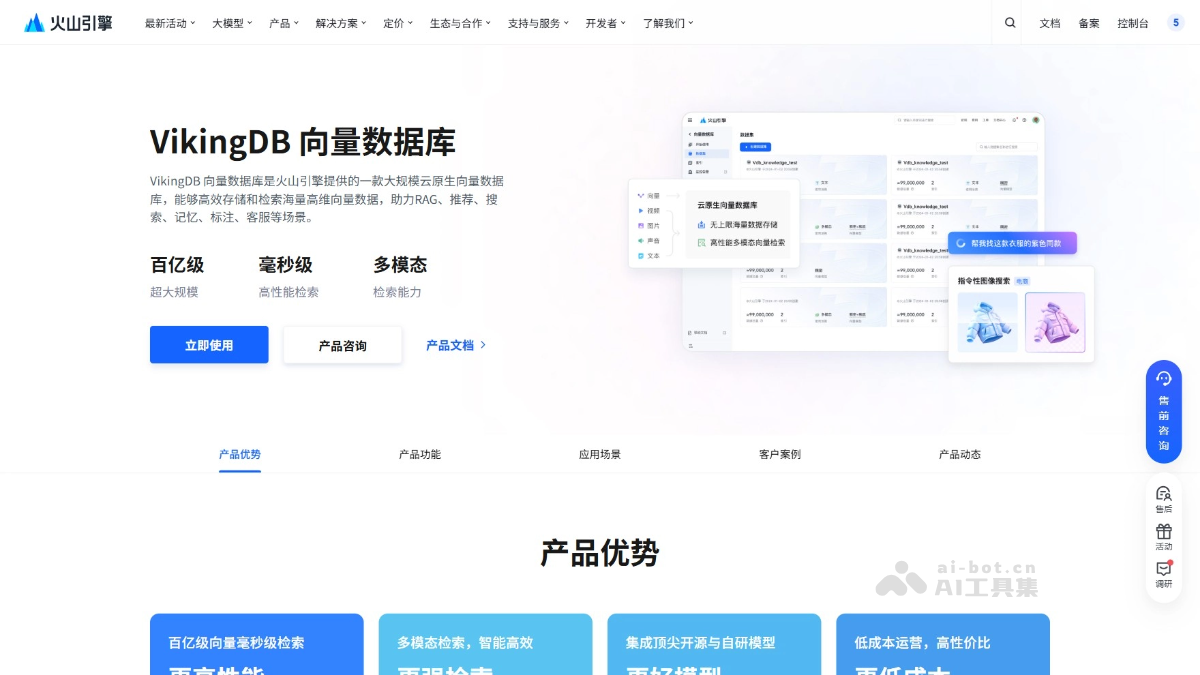
VikingDB的主要功能
- 丰富数据写入方式:支持实时同步、异步、单条数据页面写入及大规模数据批量写入,满足不同场景下的数据写入需求。
- 索引流式更新:基于自研 HNSW、IVF、DiskANN 等索引算法,结合旁路化流式更新架构,保障任意负载下的秒级数据实时性。
- 多样化检索能力:支持百亿级向量毫秒级检索,兼容向量、标量、混合及多模态数据检索,满足复杂查询需求。
- 可扩展云服务:提供 SaaS 控制台、API 和 Python/Java/Go SDK 接入,支持自动容量感知和弹性扩容,快速构建数据到检索全流程。
- 高性能与低成本:通过深度优化的索引算法和量化技术,实现百亿级向量检索 10ms 内完成,降低存储成本。
- 知识库与记忆库:提供知识库和记忆库功能,支持复杂语义检索和大模型长期记忆存储,适用个性化交互场景。
如何使用VikingDB
- 注册与登录:访问火山引擎官网:https://www.volcengine.com/product/VikingDB,注册并登录账号,进入 VikingDB 控制台。
- 创建向量数据库实例:在控制台中创建 VikingDB 实例,配置实例名称、存储容量、性能规格等参数。
- 数据准备与向量化:整理待处理数据,并用 Embedding 模型(如 Doubao 或其他开源模型)将数据转换为向量形式。
- 接入 VikingDB:安装并初始化 VikingDB 提供的 SDK(如 Python、Java、Go),连接到已创建的数据库实例。
- 写入数据:用 SDK 将向量数据写入 VikingDB,支持实时同步、异步等多种写入方式。
- 检索数据:使用 SDK 进行向量检索、标量检索或混合检索,获取最相似的结果。
- 监控与优化:在控制台监控实例性能指标,根据需要调整配置以优化性能和成本。
VikingDB的应用场景
- 多模态搜索:支持视频检索、素材版权、电商商品搜索及推荐、相似图片查找等场景,通过向量检索实现高效的内容匹配。
- 智能推荐:应用在智能推荐系统,支持大规模向量相似性搜索,帮助实现个性化推荐和内容去重。
- RAG 场景:作为 RAG(Retrieval-Augmented Generation)场景的核心组件,为大语言模型提供高效的数据检索支持。
- 记忆库:支持大模型的长期记忆存储与检索,适用角色扮演、智能硬件、教育教学、个人助手等场景的个性化交互。
- 多模态标注:基于向量检索与关键词检索结合,实现高效语义标注,支持多模态数据的标注工作。
随机内容
↑