Grok 4 – 马斯克旗下xAI推出的新一代大模型
Grok 4是什么
Grok 4 是 xAI 推出的最新AI大模型,Grok 4 的推理能力相较于前代提升 10 倍。模型具备卓越的推理能力,能在 SAT、GRE 等高难度考试中接近满分,在多项基准测试中超越其他前沿模型。Grok 4 支持多模态功能,能理解主观概念、生成代码和可视化内容,在语音交互上进行重大改进。Grok 4分为两个版本,Grok 4 是单代理(single agent)版本, Grok 4 Heavy 是多代理版本(multi agents),支持四个代理同时工作,上下文窗口最高支持 256k tokens。
Grok 4的主要功能
- 卓越的推理能力:在 SAT、GRE 等高难度考试中接近满分,展现出超越人类的推理水平。
- 多模态理解:能理解主观概念,并搜索和分析图片。
- 信息整合与摘要:从社交媒体等渠道整合信息,提取关键事件并按时间排序。
- 代码与可视化生成:根据科学提示生成复杂动画,例如模拟黑洞碰撞。
- 语音交互改进:支持五种新声音,对话更流畅,情感表达更自然。
- 复杂任务处理:在模拟经营等复杂任务中表现出色,具备强大的战略规划和执行能力。
- 并行智能体协作:SuperGrok Heavy版本,支持多个智能体并行解决复杂问题。
Grok 4的测试表现
- 官方测试:
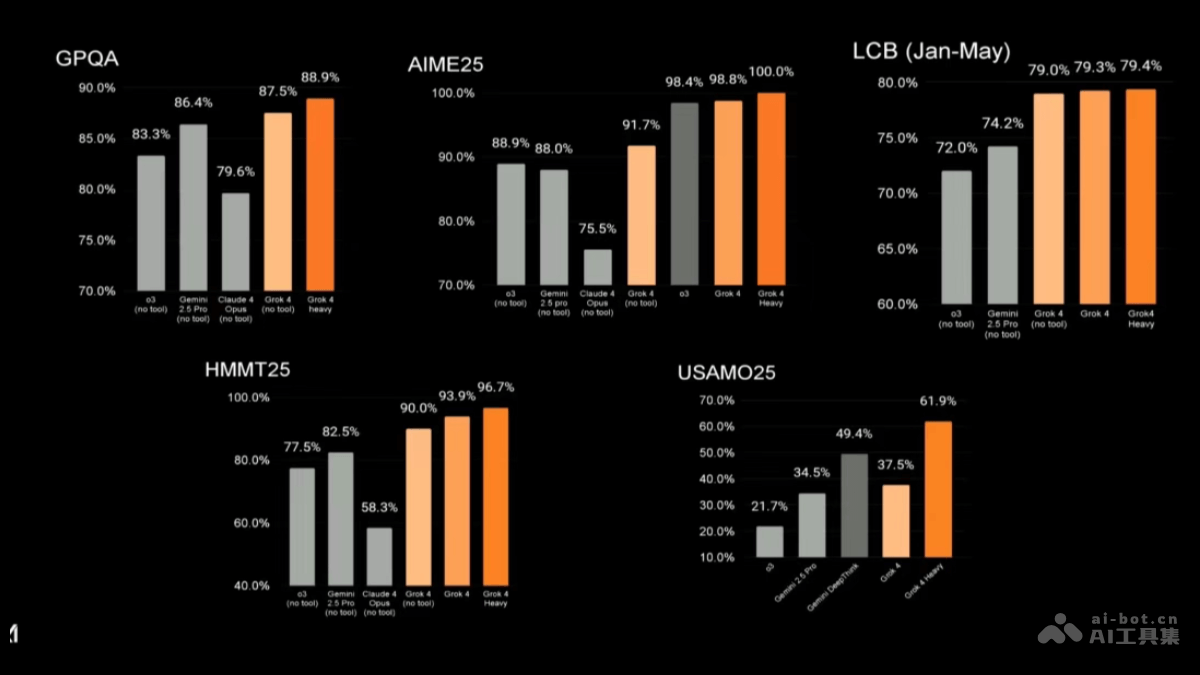
- Humanity’s Last Exam:包含 2500 个跨学科专家级问题。Grok 4 Heavy 在使用工具的情况下得分达到 44.4%,若进一步优化可提升至 50.7%。
- AIME25(数学竞赛):Grok 4 Heavy 拿到 100% 满分,碾压其他模型。
- GPQA(研究生水平问答):Grok 4 Heavy 得分 88.9%,领先于 Gemini 2.5 Pro(86.4%)和 Claude 4 Opus(79.6%)。
- HMMT25(高中数学竞赛):Grok 4 Heavy 得分 96.7%,远超 Gemini 2.5 Pro(82.5%)。
- USAMO25(美国数学奥赛):Grok 4 Heavy 得分 61.9%,大幅领先于 Gemini DeepThink(49.4%)和 Gemini 2.5 Pro(34.5%)。
- ARC-AGI(抽象推理):Grok 4 得分 15.9%,接近翻倍于之前的商业 SOTA。
- Vending-Bench(模拟经营):Grok 4 净赚 $4694,远超 Claude Opus 4($2077)和人类玩家($844)。
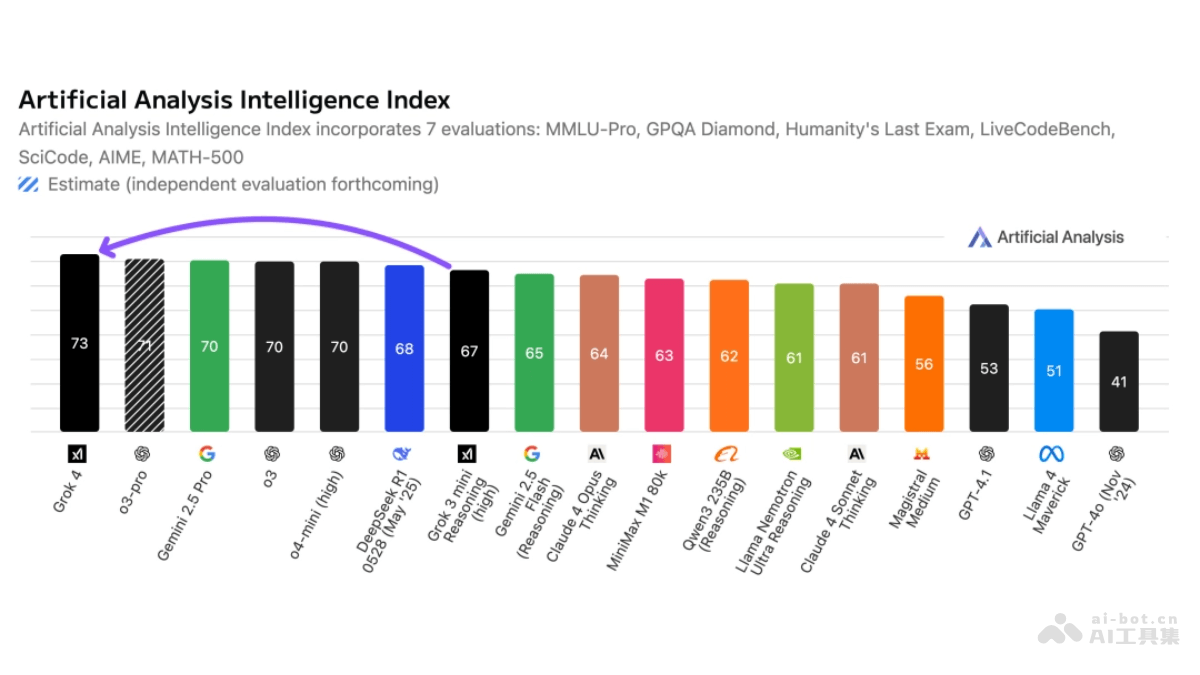
- 第三方测评(大模型性能评估平台Artificial Analysis 测试):
- 人工智能指数:Grok 4 拿到 73 分,超过 OpenAI o3(70 分)、谷歌 Gemini 2.5 Pro(70 分)、Anthropic Claude 4 Opus(64 分)和 DeepSeek R1 0528(68 分)。
- 编码指数和数学指数:Grok 4 均排名第一。
- GPQA Diamond 得分:创历史新高,达到 88%,超过 Gemini 2.5 Pro 的 84%。
- Humanity’s Last Exam 得分:创历史新高,达到 24%,超过 Gemini 2.5 Pro 的 21%。
- 速度:Grok 4 为 75 token/秒,虽不及 o3(188 token/秒)和 Gemini 2.5 Pro(142 token/秒),但优于 Claude 4 Opus Thinking(66 token/秒)。
Grok 4的产品定价
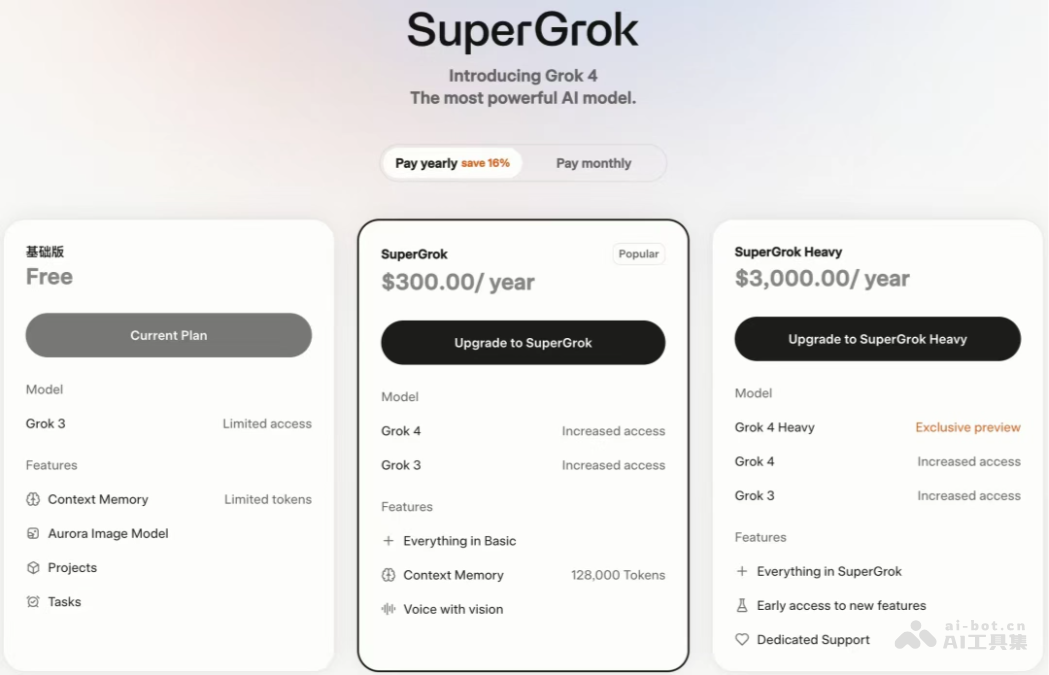
- 付费订阅计划:
- SuperGrok:年费300 美元,月费30 美元。
- SuperGrok Heavy:年费3000 美元,月费300 美元。
- API 调用定价:
- 输入:3 美元 / 百万 token。
- 输出:15 美元 / 百万 token。
Grok 4的官网地址
- 官网地址:Grok
Grok 4的应用场景
- 教育辅导:为学生提供个性化的学习方案,解答复杂的学术问题,帮助学生更好地理解和掌握知识。
- 科学研究:能够分析大量实验数据,预测科学趋势,助力科学家发现新的理论和技术。
- 商业与金融:进行市场分析和预测,为企业的商业策略制定提供数据支持,优化企业运营效率。
- 内容创作:辅助创意生成,支持广告、影视、游戏等领域的剧本撰写和动画制作,提升创作效率。
- 智能助手:作为智能语音助手,处理多模态信息,帮助用户完成日常任务,提升生活便利性。