SmolVLA – Hugging Face开源的轻量级机器人模型
芊芊下载2025-06-10 14:14:01170次浏览
SmolVLA是什么
SmolVLA 是 Hugging Face 开源的轻量级视觉-语言-行动(VLA)模型,专为经济高效的机器人设计。拥有4.5亿参数,模型小巧,可在CPU上运行,单个消费级GPU即可训练,能在MacBook上部署。SmolVLA 完全基于开源数据集训练,数据集标签为“lerobot”。
SmolVLA的主要功能
-
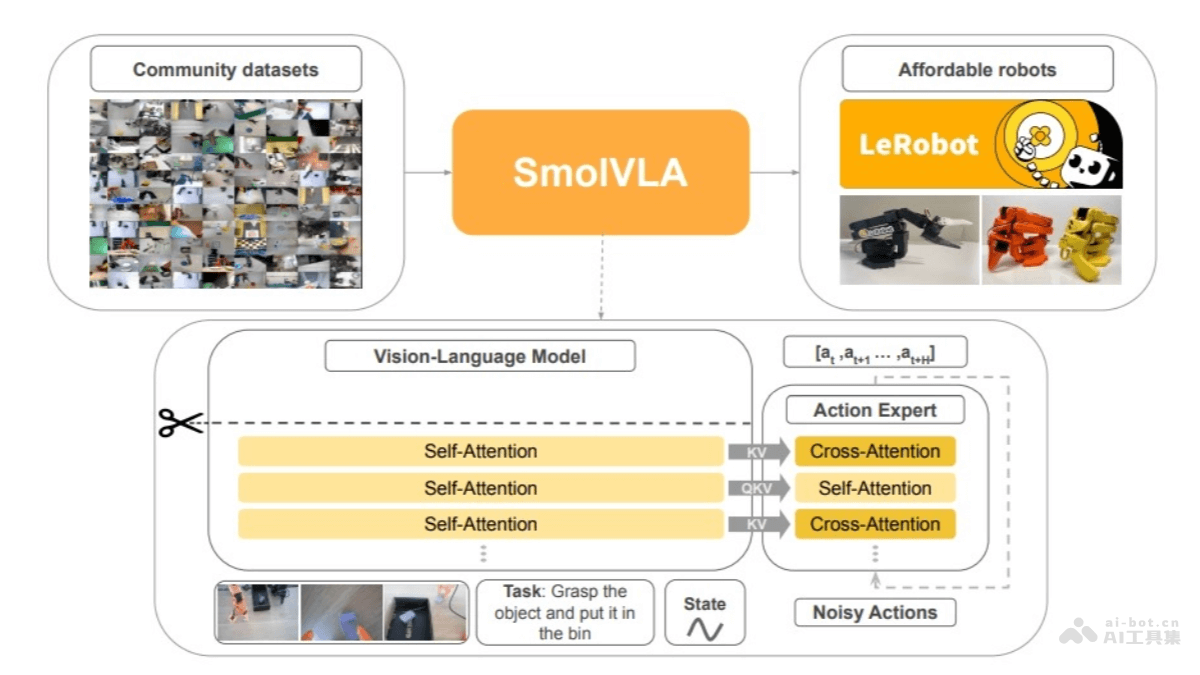
多模态输入处理:SmolVLA 能处理多种输入,包括多幅图像、语言指令以及机器人的状态信息。通过视觉编码器提取图像特征,将语言指令标记化后输入解码器,将传感运动状态通过线性层投影到一个标记上,与语言模型的标记维度对齐。
-
动作序列生成:模型包含一个动作专家模块,是一个轻量级的 Transformer,能基于视觉-语言模型(VLM)的输出,生成未来机器人的动作序列块。采用流匹配技术进行训练,通过引导噪声样本回归真实数据分布来学习动作生成,实现高精度的实时控制。
-
高效推理与异步执行:SmolVLA 引入了异步推理堆栈,将动作执行与感知和预测分离,实现更快、更灵敏的控制,使机器人可以在快速变化的环境中更快速地响应,提高了响应速度和任务吞吐量。
SmolVLA的技术原理
-
视觉-语言模型(VLM):SmolVLA 使用 SmolVLM2 作为其 VLM 主干,模型经过优化,能处理多图像输入。包含一个 SigLIP 视觉编码器和一个 SmolLM2 语言解码器。图像标记通过视觉编码器提取,语言指令被标记化后直接输入解码器,传感运动状态则通过线性层投影到一个标记上,与语言模型的标记维度对齐。解码器层处理连接的图像、语言和状态标记,得到的特征随后传递给动作专家。
-
动作专家:动作专家是一个轻量级的 Transformer(约1亿参数),基于 VLM 的输出,生成未来机器人的动作序列块。动作专家采用流匹配技术进行训练,通过引导噪声样本回归真实数据分布来学习动作生成,实现高精度的实时控制。
-
视觉 Token 减少:为了提高效率,SmolVLA 限制每帧图像的视觉 Token 数量为64个,大大减少了处理成本。
-
层跳跃加速推理:SmolVLA 跳过 VLM 中的一半层进行计算,有效地将计算成本减半,同时保持了良好的性能。
-
交错注意力层:与传统的 VLA 架构不同,SmolVLA 交替使用交叉注意力(CA)和自注意力(SA)层。提高了多模态信息整合的效率,加快推理速度。
- 异步推理:SmolVLA 引入了异步推理策略,让机器人的“手”和“眼”能独立工作。在这种策略下,机器人可以一边执行当前动作,一边已经开始处理新的观察并预测下一组动作,消除推理延迟,提高控制频率。
SmolVLA的项目地址
- HuggingFace模型库:https://huggingface.co/lerobot/smolvla_base
- arXiv技术论文:https://arxiv.org/pdf/2506.01844
SmolVLA的应用场景
- 物体抓取与放置:SmolVLA 可以控制机械臂完成复杂的抓取和放置任务。例如,在工业生产线上,机器人需要根据视觉输入和语言指令,准确地抓取零件并将其放置到指定位置。
- 家务劳动:SmolVLA 可以应用于家庭服务机器人,帮助完成各种家务劳动。例如,机器人可以根据自然语言指令,识别并清理房间中的杂物,或者将物品放置到指定位置。
-
货物搬运:在物流仓库中,SmolVLA 可以控制机器人完成货物的搬运任务。机器人可以根据视觉输入识别货物的位置和形状,结合语言指令,生成最优的搬运路径和动作序列,提高货物搬运的效率和准确性。
- 机器人教育:SmolVLA 可以作为机器人教育的工具,帮助学生和研究人员更好地理解和开发机器人技术。
随机内容
↑